Cloud computing is one of the latest trend in Enterprise IT. Like any other technology it has its own benefits and pitfalls. For any enterprise to ride over cloud, readiness must be assessed.
The following steps will help any enterprise to adopt cloud:
1. Build/Break the Business Case: While money is always a big factor but does Cloud fits well with business requirements (current and future – geographical expansion, merger/de-merger & acquisition/hive-off, alliances, legal & compliance, new product introduction etc), current technical & business architecture (current & future). If you are able to make a business case then proceeds.
2.Take stock of the application portfolio: What are current applications in service and at what stage of life cycle. Those are at end of their life, what to be done with them - should be upgraded with newer versions if available or some thing new (Off the shelf, custom application or extension of existing application/s) or discarded? Which applications will not be required in immediate future and not so immediate future due to business architectural changes (current and envisioned)? What are the acquisition plans for newer applications – off the shelf, custom and extensions?
3.Take stock of Cloud offerings and Rank them: There are numerous cloud offerings in market from variety of players. Assess them based on their offerings and evaluate them on the basis of your requirements:
a. Business Architecture: Security, SLAs, compliances, proprietary & generic processes, out sourcing, usability, scalability, etc
b. Technical Architecture: layer of cloud architecture, data control, data movement, DR mechanism, backup mechanism, upgrading plan, audibility, etc
c. Financial Details: Licensing challenges of applications on the cloud, price structure of cloud offering, training and skill upgrading cost, process modification cost, data movement cost, etc
While taking stock of cloud offerings consider options of Public, Private and Hybrid clouds.
4.Do Proof of concepts (PoCs): Zero in at couple of Cloud offerings (preferably three to five) and develop PoCs. These PoCs must be simple but complex enough to cover meaningful business case. Evaluate these PoCs and do scrutiny from Business, Technical and Financial perspectives to get clouds (cloud itself and cloud offerings) implication on the enterprise. Now choose one or two cloud offerings.
5. Pick the low hanging fruits: Once PoCs are successful and crosses Business, Technical and Financial barriers zero in on chosen offerings. Pick some low hanging fruits and move them to Cloud. Perform detailed scrutiny of each project to fine tune the whole strategy.
6.Do resource planning: Migrating from server management to cloud management requires drastic change in planning matrix. Enterprise requires different kind of skill set to manage cloud. Enterprise requires different kind of tools and techniques to manage clouds.
7.Pick up some high visibility but less critical projects: Once every thing is in place, it is time to pick up some high visibility but less critical projects. This will make cloud visible to various stake holders with minimal risk.
8. March to Cloud
Friday, December 25, 2009
Thursday, December 24, 2009
The Hidden Cost of Cloud Computing
One of the most obvious benefits of Cloud Computing is conversion of CaEx to OpEx which brings in cost reduction. But one must remember there are no free lunches. Cloud Computing has its own set of hidden costs which must be considered while deciding about.
1. What are the viable paths to move or replace legacy application into cloud?
2. What are the changes required to integrate cloud or non cloud applications?
3. What technological and business processes will change to take benefits of Cloud?
4. What are the trade offs of using Private/Public/Hybrid clouds for each application?
5. What are the skills to be acquired and/or upgraded to take benefit of Cloud?
I have just listed Whats but to get insight do 5 Wives and 2 Husbands Analysis.
1. What are the viable paths to move or replace legacy application into cloud?
2. What are the changes required to integrate cloud or non cloud applications?
3. What technological and business processes will change to take benefits of Cloud?
4. What are the trade offs of using Private/Public/Hybrid clouds for each application?
5. What are the skills to be acquired and/or upgraded to take benefit of Cloud?
I have just listed Whats but to get insight do 5 Wives and 2 Husbands Analysis.
Saturday, December 12, 2009
Template Based Design Technique - Part 3
In the past I was talking about Template based design. Here is the last blog in that series which talk about giving facility to create Master template.
1. Template Based Design Technique - Part 1
2. Template Based Design Technique - Part 2
Design Approach
During designing various systems for small and large companies, we have faced constant challenge of scalability, flexibility, performance. To tackle few of these challenges, we have developed our own pattern. It is named as Template Driven Design or the Template Pattern.
In a template pattern, the model (data such as XML,) has no inherent knowledge of how it would be utilized. The actual algorithm is delegated to the views, i.e. templates. Templates are applied to the different set of data and produce different results. Thus, it is a subset of model-view-controller patterns without the controller. For example, different XSLT templates could render the different XML data and produce different outputs.
Let us take an example to understand the challenge and then ways to resolve the same. We are very familiar with Microsoft Word. The users of MS Word can create template and further they can create document using templates. Suppose I wish to create my resume, I can use one of the several resume templates it provides to make one of mine. So now keeping template creation facility in view the whole process can be depicted as:

In this process “Resume Template” and “Resume“ have separate and distinct life cycles. Destruction of Resume does not affect “Resume Template”. Similarly destruction of “Resume Template “ does not affect “Resume “ once it is created.
This design pattern can be further explained below as:
1. If God is imaginative enough, he can accommodate all type of fields in his template even those will be required in future. We can consider God’s creation as Master Template which gives wisdom to angels to create Templates. In this terminology the “Master Template creator” acts as God. Assuming that the GOD knows only present in that case list of attributes are not final and it will not remain same for ever. Since GOD learns various new tricks over time period, so Master Template is not fixed and it also evolves over time period.
2. God can appoint various Angels (Template Creators), who can use one of the “Master templates” and can create templates for specialized purpose.
3. Now Human Beings (Resume Creators) can use one of the “Resume Templates” and can create various resumes.
So now question arises on how to implement same design pattern in a business application which could be web based. Assuming that the application is a web application and it is user creation service. Now keeping Template creation facility in view, the whole process of user creation service can be depicted as:

Let’s assume that God creates Master Template “MT1” with the following fields:
1. User Name
2. First Name
3. Middle Name
4. Last Name
5. Remarks
6. Gender
7. Status
Now the Angel (Template Creator) chooses the above Master template “MT1” and the following page will be displayed. (The significance of the other fields as mentioned below in the page, will be explained later in the document)

Now the Angel creates User Template “UT1” as shown below, with all the fields as specified in Master Template:

The user now chooses the above template “UT1” to create a new user and following page is displayed.

The user now fills this form with the following values:
User Name: Shilpi
First Name: Shilpi
Middle Name: Asnani
Last Name: Asnani
Remarks: Form created
Gender: Female
Status: Active
When the user clicks on save button, the data is stored in database. The data can be viewed back in following form:

Implementations Details
The following diagram covers the flow explained above. Also the Create/ Read/ Update/ Delete (CRUD) operations on form and Templates are covered in following sections.
GUI Interface component, as specified in diagram below, is used to generate master template XML documents. The XML file is compliant with the Master Template Schema.
After generation of XML file, a XSL designed for the Master Template is used to transform this XML document into HTML (Master Template).
Now on this HTML page (Master Template) the values are entered and data is saved in a XML file. The XML file is compliant with the Template Schema. The XSL designed for Templates is used to transform the XML document into HTML (Template).
The values are entered on the HTML (Template) page. On the click of the ‘save’ button by the user, the values are stored in the in a XML file/ database. The persistent XML is compliant with the ‘Generic Form’ schema.
To update the values, the data is retrieved from the database and a XML file is generated. Further an XSL designed for generic form is used to transform this XML document into HTML (Generic Form).On this HTML (Form) the values are edited and data is saved back into database.

Functional details:
Pre-requisite
• Copy all the schema files and XSL from the zip file in the directory “C:\Templates”
• Deploy the project “TemplateApproachProj” on JBoss
• Restore the SQL dump from the zip file in MySQL
The whole process flow is divided into 3 parts:
• Generate Master Template
• Generate Template
• Generate Forms
Generate Master Template
When the project (TemplateApproachProj) is launched then following screen is displayed:

The screen is used to generate Master Templates. The functionality of all the fields are explained below:
Master Template Name: This is the name of the Master Template
Master Template Description: This is the description of the Master Template
Field Name: The name of the field to be displayed on the form (e.g.: username)
Visibility: Two radio buttons indicating field’s display while creating a new form.
VisibilityInfoDisabled: If yes, then Angel can’t change the visibility status.
Mandatory: Two radio buttons specifying whether field is mandatory or optional while creating a new form.
MandatoryInfoDisabled: If yes, then Angel can’t change the mandatory status.
Input Type :Field on the form can be one of the 6 input types as listed below:
TextBox
TextArea
RadioButtonGroup
CheckBoxGroup
SingleSelectDropList
MultiSelectDropList
Specify Values for DropList: Specify the comma separated list of values for SingleSelectDropList, MultiSelectDropList, CheckBoxGroup, RadioButtonGroup input types.
JS File Required: If yes, then Angel can associate JS file.
Browse Button: Is used to select Master Template XML file.
Ok Button: Is used to create Master Template XML document with single element.
One More: Is used to create or add more elements in Master Template XML document.
Preview XML: Is used to view the elements of Master Template.
Let us create a Master Template. So specify the following details on the form (fig 2.1):
Master Template Name as “MT1”
Master Template Description as “Master Template added”
Field Name as “UserName”
Click “Yes” for JS File Required.
Click “One More“ button
Field Name as “Gender”
Input Type as “SingleSelectDopList”
Specify Values for DropList as “Male,Female,Not willing to reveal”
Click “One More” button.
Now the Master template file “MT1.xml “is generated at path “c:/Templates”.
Click on browse button to select Master Template XML file “MT1.xml “created above.
Click on “submit” button
The (Master Template) HTML page (fig 2.2) is displayed.
Note:
1. The convention is that the name of the Master Template XML file is name of the
Master Template.
2. All the templates will be stored at location “c:\Templates”.
Generate Template
After clicking the ‘Submit’ button as mentioned above, following screen will be displayed

This HTML form (Master Template) is used to generate Template. The functionality of all the fields are explained below:
Name: This is the name of the Template
Description: This is the description of the Template
Visibility: Checkbox indicating field’s display while creating a new form.
Mandatory: Two radio buttons specifying whether field is mandatory or optional while creating a new form
Validation File: Specify the path of the js file. The convention is that the name of the function in js file should follow the following format.
function func_fieldname(fieldId)
{
}
*The fieldname is the name of the field with which js file is associated.
*The input parameter fieldId is the id of the fieldname.
Event :Specify the event, on which the function in js file will be invoked, for that particular field of the form
Let us create a Template. So specify the following details on the form (Fig 2.2):
Template Name as “UT1”
Template Description as “Template added”
Validation File as “test.js”
Event as “onchange”
Click “Save” button.
Now the template file “UT1.xml “ is generated at path “c:/Templates”.
The below mentioned screenshot fig 2.3 is displayed
Click on browse button to select Template XML file “UT1.xml “created above.
Click on submit button
The (Template ) HTML page (fig 2.4) is displayed
Note: The convention is that the name of the Template XML file is name of the Template.

Generate Object
After clicking the submit button as mentioned above following screen will be displayed
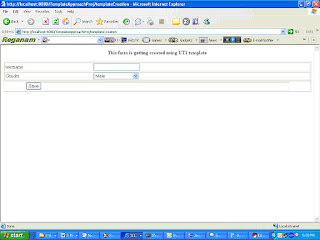
The values are entered on the HTML(Template) page. On the click of the ‘save’ button, a user is created.
The field username/Gender displayed on the above screen was specified in Master Template/Template.
Let us create a user. So specify the following details on the form:
User Name as “Shilpi”
Gender as “Female”
Click “Save” button.
Data is saved in database.
The below mentioned screenshot (fig 2.5) is displayed
Click on id (let say object id 47) created above.
The data is retrieved from database and displayed on HTML page(fig 2.6)
Change username as “ShilpiAsnani”
Click on save button
The data is updated in database and the below mentioned screenshot (Fig 2.7) is displayed



1. Template Based Design Technique - Part 1
2. Template Based Design Technique - Part 2
Design Approach
During designing various systems for small and large companies, we have faced constant challenge of scalability, flexibility, performance. To tackle few of these challenges, we have developed our own pattern. It is named as Template Driven Design or the Template Pattern.
In a template pattern, the model (data such as XML,) has no inherent knowledge of how it would be utilized. The actual algorithm is delegated to the views, i.e. templates. Templates are applied to the different set of data and produce different results. Thus, it is a subset of model-view-controller patterns without the controller. For example, different XSLT templates could render the different XML data and produce different outputs.
Let us take an example to understand the challenge and then ways to resolve the same. We are very familiar with Microsoft Word. The users of MS Word can create template and further they can create document using templates. Suppose I wish to create my resume, I can use one of the several resume templates it provides to make one of mine. So now keeping template creation facility in view the whole process can be depicted as:

In this process “Resume Template” and “Resume“ have separate and distinct life cycles. Destruction of Resume does not affect “Resume Template”. Similarly destruction of “Resume Template “ does not affect “Resume “ once it is created.
This design pattern can be further explained below as:
1. If God is imaginative enough, he can accommodate all type of fields in his template even those will be required in future. We can consider God’s creation as Master Template which gives wisdom to angels to create Templates. In this terminology the “Master Template creator” acts as God. Assuming that the GOD knows only present in that case list of attributes are not final and it will not remain same for ever. Since GOD learns various new tricks over time period, so Master Template is not fixed and it also evolves over time period.
2. God can appoint various Angels (Template Creators), who can use one of the “Master templates” and can create templates for specialized purpose.
3. Now Human Beings (Resume Creators) can use one of the “Resume Templates” and can create various resumes.
So now question arises on how to implement same design pattern in a business application which could be web based. Assuming that the application is a web application and it is user creation service. Now keeping Template creation facility in view, the whole process of user creation service can be depicted as:

Let’s assume that God creates Master Template “MT1” with the following fields:
1. User Name
2. First Name
3. Middle Name
4. Last Name
5. Remarks
6. Gender
7. Status
Now the Angel (Template Creator) chooses the above Master template “MT1” and the following page will be displayed. (The significance of the other fields as mentioned below in the page, will be explained later in the document)

Now the Angel creates User Template “UT1” as shown below, with all the fields as specified in Master Template:

The user now chooses the above template “UT1” to create a new user and following page is displayed.

The user now fills this form with the following values:
User Name: Shilpi
First Name: Shilpi
Middle Name: Asnani
Last Name: Asnani
Remarks: Form created
Gender: Female
Status: Active
When the user clicks on save button, the data is stored in database. The data can be viewed back in following form:

Implementations Details
The following diagram covers the flow explained above. Also the Create/ Read/ Update/ Delete (CRUD) operations on form and Templates are covered in following sections.
GUI Interface component, as specified in diagram below, is used to generate master template XML documents. The XML file is compliant with the Master Template Schema.
After generation of XML file, a XSL designed for the Master Template is used to transform this XML document into HTML (Master Template).
Now on this HTML page (Master Template) the values are entered and data is saved in a XML file. The XML file is compliant with the Template Schema. The XSL designed for Templates is used to transform the XML document into HTML (Template).
The values are entered on the HTML (Template) page. On the click of the ‘save’ button by the user, the values are stored in the in a XML file/ database. The persistent XML is compliant with the ‘Generic Form’ schema.
To update the values, the data is retrieved from the database and a XML file is generated. Further an XSL designed for generic form is used to transform this XML document into HTML (Generic Form).On this HTML (Form) the values are edited and data is saved back into database.

Functional details:
Pre-requisite
• Copy all the schema files and XSL from the zip file in the directory “C:\Templates”
• Deploy the project “TemplateApproachProj” on JBoss
• Restore the SQL dump from the zip file in MySQL
The whole process flow is divided into 3 parts:
• Generate Master Template
• Generate Template
• Generate Forms
Generate Master Template
When the project (TemplateApproachProj) is launched then following screen is displayed:

Fig:2.1
The screen is used to generate Master Templates. The functionality of all the fields are explained below:
Master Template Name: This is the name of the Master Template
Master Template Description: This is the description of the Master Template
Field Name: The name of the field to be displayed on the form (e.g.: username)
Visibility: Two radio buttons indicating field’s display while creating a new form.
VisibilityInfoDisabled: If yes, then Angel can’t change the visibility status.
Mandatory: Two radio buttons specifying whether field is mandatory or optional while creating a new form.
MandatoryInfoDisabled: If yes, then Angel can’t change the mandatory status.
Input Type :Field on the form can be one of the 6 input types as listed below:
TextBox
TextArea
RadioButtonGroup
CheckBoxGroup
SingleSelectDropList
MultiSelectDropList
Specify Values for DropList: Specify the comma separated list of values for SingleSelectDropList, MultiSelectDropList, CheckBoxGroup, RadioButtonGroup input types.
JS File Required: If yes, then Angel can associate JS file.
Browse Button: Is used to select Master Template XML file.
Ok Button: Is used to create Master Template XML document with single element.
One More: Is used to create or add more elements in Master Template XML document.
Preview XML: Is used to view the elements of Master Template.
Let us create a Master Template. So specify the following details on the form (fig 2.1):
Master Template Name as “MT1”
Master Template Description as “Master Template added”
Field Name as “UserName”
Click “Yes” for JS File Required.
Click “One More“ button
Field Name as “Gender”
Input Type as “SingleSelectDopList”
Specify Values for DropList as “Male,Female,Not willing to reveal”
Click “One More” button.
Now the Master template file “MT1.xml “is generated at path “c:/Templates”.
Click on browse button to select Master Template XML file “MT1.xml “created above.
Click on “submit” button
The (Master Template) HTML page (fig 2.2) is displayed.
Note:
1. The convention is that the name of the Master Template XML file is name of the
Master Template.
2. All the templates will be stored at location “c:\Templates”.
Generate Template
After clicking the ‘Submit’ button as mentioned above, following screen will be displayed

Fig 2.2
This HTML form (Master Template) is used to generate Template. The functionality of all the fields are explained below:
Name: This is the name of the Template
Description: This is the description of the Template
Visibility: Checkbox indicating field’s display while creating a new form.
Mandatory: Two radio buttons specifying whether field is mandatory or optional while creating a new form
Validation File: Specify the path of the js file. The convention is that the name of the function in js file should follow the following format.
function func_fieldname(fieldId)
{
}
*The fieldname is the name of the field with which js file is associated.
*The input parameter fieldId is the id of the fieldname.
Event :Specify the event, on which the function in js file will be invoked, for that particular field of the form
Let us create a Template. So specify the following details on the form (Fig 2.2):
Template Name as “UT1”
Template Description as “Template added”
Validation File as “test.js”
Event as “onchange”
Click “Save” button.
Now the template file “UT1.xml “ is generated at path “c:/Templates”.
The below mentioned screenshot fig 2.3 is displayed
Click on browse button to select Template XML file “UT1.xml “created above.
Click on submit button
The (Template ) HTML page (fig 2.4) is displayed
Note: The convention is that the name of the Template XML file is name of the Template.

Fig 2.3
Generate Object
After clicking the submit button as mentioned above following screen will be displayed

Fig 2.4
The values are entered on the HTML(Template) page. On the click of the ‘save’ button, a user is created.
The field username/Gender displayed on the above screen was specified in Master Template/Template.
Let us create a user. So specify the following details on the form:
User Name as “Shilpi”
Gender as “Female”
Click “Save” button.
Data is saved in database.
The below mentioned screenshot (fig 2.5) is displayed
Click on id (let say object id 47) created above.
The data is retrieved from database and displayed on HTML page(fig 2.6)
Change username as “ShilpiAsnani”
Click on save button
The data is updated in database and the below mentioned screenshot (Fig 2.7) is displayed

Fig 2.5

Fig 2.6

Fig 2.7
Database Archival Utility
1. Introduction

In any enterprise class application physical delete of data is not a choice. There exist only logical delete. But logical delete brings its own challenges. Logical delete of data brings in ever growing tables which keep on slowing the database.
To overcome problem of growing data, in my recent application, I have architected and designed a utility which will move physically deleted data from application tables to archival tables. Archival tables essentially keep deleted records.
This utility is in two parts. Part 1, converts database schema in an XML file where it is marked that which tables to be archived and which are not. Part 2 of the utility does actual movement of data.
2. Database Schema
Database schema can be though of consists of three categories of tables:
• Master-Master Table
• Master Table
• Transaction tables
Master-Master tables are those tables which contain seed data for an application. This data is independent of any user and its operations. Example - Table containing the name of Countries etc.
Master Tables are those tables which are pivotal to an application and hold information like users etc.
Transaction tables are those tables which stores information about all the transaction performed by/on the entities stored in Master tables.
The relationship among tables can be thought of two types:
• Imported: primary keys of other tables referenced
• Exported: tables which refer table1’s primary key
This relationship among tables can grow up to any depth.
To understand please refer following picture:

Table table1 has imported primary key from table2, which in turn has imported keys from table5 and table6 and exported its primary key to table3 and table4. Table table1 also exported its primary key to table7 which in turn has imported primary keys from table8 and table9 and exported its primary key to table10 and table11.
Apart from these relationships, a well designed database schema must not have any circular relationships among tables.
3. Utility Parts
Data archival utility consists of two parts.
• Part 1- Database Relation XML generator Utility: This utility create an XML representation of Database Schema where some one marks each table into said categories (Master-Master, Master and Transaction tables)
• Part 2- Database Archival Utility: This utility is designed for moving, logically deleted records from the Main Database of application to the Archival database of application. DB Archival utility archives records for:
• Master tables
• Transaction tables in Xing
As Master-Master tables contain only static records, its unnecessary burden on utility to move these records to archival database. Instead it is left to the database administrator to copy records from Main Database’s Master-Master tables to Archival database’s Master-Master tables.
4. Database Relation XML generator Utility
Relation XML generator reads a property file to capture credentials to connect to Main database for generating table relations. This property file contains information about the main database. Structure of property files are described at end of Description section of this document.
Relation XML generator reads another property file to identify table for which relation XML is to be generated.
This Utility must be executed after every schema update.
5. Database Archival Utility
DB Archival utility is architected and designed for moving, deleted records from the Main Database to the Archival database. DB Archival utility archives records for:
• Master tables
• Transaction tables
As Master-Master tables contain only static records, its unnecessary burden on utility to move these records to archival database. Instead it is left to the database administrator to copy records from Main Database’s Master-Master tables to Archival database’s Master-Master tables.
DB Archival utility archive records table wise.
Database Archival utility reads a property file to capture credentials to connect to Main database. It also reads another property file to capture Archival database credentials to connect to Archival database.
Database archival utility runs continuously but archives data on specified time only. This time can be specified in a scheduling property file. This file provides information about when to move the deleted records to Archival database.
Database archival utility archives only those deleted records for which the specified timeframe (delay time) has expired since the record was deleted. Currently this timeframe is common for all tables. This timeframe (Delay time) is specified in a property file.
Database Archival utility reads property file to identify tables, which are to be archived. Then for each table, it reads its relationship XML generated by Database Relationship XML Generator, and moves the deleted records to Archival database tables from Main database tables.
Copy and Delete operations
• DB archival utility copies all imported records to archival database tables to avoid any database constraint failure.
• DB archival utility first copies all exported records to archival database tables then delete them from main database tables.
E.g. Lets assume table1 is specified for database archival
.
Exported and Imported tables for table1 are specified in a XML file, created by DB relation XML generator.
DB Archival utility finds all the rows in table1 to be archived i.e. rows in table where status is “Delete” and these deleted records are older than the delay time specified.
DB archival utility reads the XML file for table1 for finding all the tables which are referenced by table1 (Exported Table List) and all tables referenced by table1 (Imported table List).
DB Archival utility copies data of related imported relations to respective archive tables for a particular table (table1).
For exported relation’s DB Archival utility copies to respective archival table and delete the records from main table and all subsequent tables. If any table is imported in exported Table of table1 then its record is only copied to respective archival table.
DB archival utility copy imported table’s data accessed by records to be archived in the table. This procedure is recursive and copies all the data down the hierarchy in the imported table list.
Then DB archival utility copies the exported table’s data to archival table and deletes them from main tables. This procedure is recursive and copies all the data down the hierarchy in the exported table list.
6. Property File Structure
Five property files are used in Database Relation XML generator and DB Archival Utility. Structure of all property files is described below:
• DBCredentials.properties: This property file is read by both utilities to connect to Main database. This file have following keys, all values must be specified and supports only single values.
a. DATABASE_DRIVER
b. DATABASE_IP
c. DATABASE_PORT
d. DATABASE_NAME
e. DATABASE_USER_ID
f. DATABASE_USER_PASSWORD
g. DATABASE_PROTOCOL
• ArchiveDBCredentials.properties: This property file is read by DB Archival utility to connect to Archival database. This file have following keys, all values must be specified and supports only single values.
a. DATABASE_DRIVER
b. DATABASE_IP
c. DATABASE_PORT
d. DATABASE_NAME
e. DATABASE_USER_ID
f. DATABASE_USER_PASSWORD
g. DATABASE_PROTOCOL
• Scheduler.properties: This property file holds information for Scheduler of Archival utility. This file have following keys:
a. SECONDS
b. MINUTES
c. HOURS
d. DAY-OF-MONTH
e. MONTH
f. DAY-OF-WEEK
• TablesToArchive.properties: This property file is read by both utilities to identify Tables to archive. An additional value is read by Database Relation XML generator to identify Master-Master Tables. All other values are read by DB Archival utility. This property file have following keys:
a. TABLE_TO_ARCHIVE
b. MASTER_MASTER_TABLE_LIST
c. Delay time must be specified in property file against appropriate key. By default all keys are set to 0.
archivalDelayTime_second=0
archivalDelayTime_minute=0
archivalDelayTime_hour=0
archivalDelayTime_day=0
Delay time specifies the time duration after which deleted entity is moved to archival database’s table. Everything must be specified in INTEGER. The least time that can be specified is 0 second.
d. All table names in Main database as key and corresponding table name in archival database as value. All keys and values must be specified in small cases. Although only specifying tables which are in relationship with tables in TABLE_TO_ARCHIVE key will suffice, but to reduce probability of any error provide all tables.
e. Column names of last modified time and current status for all tables to archive must be specified in following manner:
tableName_LAST_MODIFIED_TIME
tableName_CURRENT_STATUS
tableName must be provided in small cases. Values for above key must be columns representing LAST_MODIFIED_TIME and CURRENT_STATUS column in respective tables.
7. Assumption in database archival utility
• All relationships in database are maintained at Database level not at code level.
• Archival Database structure will be same as Main database. All relationships will be maintained in archival database too.
• Archival tables must contain one and only one additional column for archival timestamp except for Master-Master table.
• Column names in archival tables must be same as column names in main database table except the archival timestamp column. All other RDBMS components (trigger, stored procedures etc) may not be needed in archival database as it contains only deleted records. If in any case (e.g. reporting etc) any RDBMS components is/are needed they must be modified according to archival Database and ported manually or some other means. Above operation is out of scope for DB Archival utility.
• Tables to archive must be specified in a property file.
• Tables to archive must have a status column and last modification time column. Last modification time column must be stored as timestamp, if it is stored as date, then time part (HH:MM:SS) of date is considered as 00:00:00. Actual column names for status and last modified time must be specified in property file against key
o tableName_LAST_MODIFIED_TIME
o tableName_CURRENT_STATUS
• Archival table names must be specified in property file against there table names as key.
• Deleted records must have there status “Delete” or “delete” or “DELETE” or any possible lower and upper case version of “DELETE”.
Friday, December 4, 2009
Architectural Consideration for application to be deployed over Cloud
Cloud computing is new way of deploying a application. This deployment topology brings in its own pleasant moments and surprises. For an architect and designer Cloud opens up new avenue and dent into capacity planning. Now a programmer of application to be deployed on a cloud can spread over logical hardware at run time without involvement of any hardware and network person’s involvement.
While architecting a application for Cloud few aspects to be taken into consideration.
1. Scale: Application to be deployed on Cloud can grow and shrink dynamically based on load and can be controlled programmatically.
2. Coupling: Application to be developed in highly loosely coupled. Here SOA principles can come handy.
3. Clustering and Virtualization: Clustering and Virtualization is inherent to cloud architecture. These two aspects must be considered in detail while architecting an application.
4. Failure: Clod application must be architected to fail in parts, autonomic and fault tolerant fashion to get full benefits of Cloud architecture.
These are the considerations specific to Cloud. There could be several other which we can learn with experience over Cloud.
While architecting a application for Cloud few aspects to be taken into consideration.
1. Scale: Application to be deployed on Cloud can grow and shrink dynamically based on load and can be controlled programmatically.
2. Coupling: Application to be developed in highly loosely coupled. Here SOA principles can come handy.
3. Clustering and Virtualization: Clustering and Virtualization is inherent to cloud architecture. These two aspects must be considered in detail while architecting an application.
4. Failure: Clod application must be architected to fail in parts, autonomic and fault tolerant fashion to get full benefits of Cloud architecture.
These are the considerations specific to Cloud. There could be several other which we can learn with experience over Cloud.
Friday, November 20, 2009
B2B Integration Reference Architecture
With the advent of internet and increasing globalization of business B2B has gained predominance. More over increasing complexities in business processes and sheer increase in inter business transactions is forcing B2B integration in big way. On the technology side, emergence of SOA, BPM and Cloud Computing has changed thought about integration.
Keeping in mind Business and Technological factors, I have developed a B2B Integration architecture which is platform and vendor neutral.

The bottom most Enterprise IT Assets block represents Business & Technical Applications and Services. These IT assets may be in form of packaged solutions or in house developed. These assets consist of in-house hosted solutions as well as ASP or SaaS like solutions. This layer provides information processing and persistence capality to fulfill business needs.
In any typical business organization, two protect IT assets DMZ is implemented using two firewalls. In the proposed Reference B2B Integration architecture, DMZ hosts B2B Gateways Proxy to surrogate real B2B Gateways. Just between B2B Gateway and inner firewall, Entity Management layer resides to resolve identity of incoming requests. On successful entity resolution requests are passed to B2B Gateway layer which is essentially a message transformer.
B2B Gateway passes the message to ESB which with help of Trading Partner Agreement Enforcer passes to appropriate piece of IT asset for processing.
Similarly Outgoing requests are passed to partner from Enterprise IT assets.
Keeping in mind Business and Technological factors, I have developed a B2B Integration architecture which is platform and vendor neutral.

The bottom most Enterprise IT Assets block represents Business & Technical Applications and Services. These IT assets may be in form of packaged solutions or in house developed. These assets consist of in-house hosted solutions as well as ASP or SaaS like solutions. This layer provides information processing and persistence capality to fulfill business needs.
In any typical business organization, two protect IT assets DMZ is implemented using two firewalls. In the proposed Reference B2B Integration architecture, DMZ hosts B2B Gateways Proxy to surrogate real B2B Gateways. Just between B2B Gateway and inner firewall, Entity Management layer resides to resolve identity of incoming requests. On successful entity resolution requests are passed to B2B Gateway layer which is essentially a message transformer.
B2B Gateway passes the message to ESB which with help of Trading Partner Agreement Enforcer passes to appropriate piece of IT asset for processing.
Similarly Outgoing requests are passed to partner from Enterprise IT assets.
Wednesday, November 18, 2009
Cloud Computing Demystified
What is cloud computing? No one knows. Every one has his own definition to suite his needs. To add to confusion I also add my two cents to definition of cloud.
In my point of view cloud computing is an umbrella term for XaaS and virtualized IT assets supported by Utility, Grid and Autonomic Computing in one offering. But due to early in life cycle of evolution not all cloud offering are based on Utility, Grid and Autonomic computing principles. X in XaaS has many metaphors and there also exist great divide among analysts, vendors and service providers.

Infrastructure as s Service (IaaS): This is Data Centre as a Service or remotely managed data center.
Storage as a Service: This is Disk Space as a Service or in simple terms Disk Space on Demand. You can consider this as remote storage for consumer but local for application.
Database as a Service (DaaS): This service provides consumers to access and manage persistence layer (RDBMS, Hierarchal Database – LDAP, File System, etc).
Information as a Service: This is granular business services on demand. For example tax calculation for a product/service.
Software as a Service (SaaS): This is Application as a Service. Here a major portion of or full business application is offered on demand. On the extreme of Cloud is Process as a Service (process outsourcing).
Integration as a Service: It is one of the most interesting aspects of Cloud. It provide features of traditional EAI/B2B but as service.
Platform as a Service (PaaS): This is offering provide complete SDLC of Cloud hosted application/service. Most of the matured Clouds provide this service by default.
Governance as a Service: This is basically mechanism to manage cloud computing resources, typically managing topology, resource utilization, up time, policy management and other related issues.
Testing as a Service: This is facility provides sandbox testing of developed application/service using PaaS offering.
Security as a Service: Due to open nature of internet, security is must for any offering. Security as a service may offer identity management, encryption/decryption, etc.
In my point of view cloud computing is an umbrella term for XaaS and virtualized IT assets supported by Utility, Grid and Autonomic Computing in one offering. But due to early in life cycle of evolution not all cloud offering are based on Utility, Grid and Autonomic computing principles. X in XaaS has many metaphors and there also exist great divide among analysts, vendors and service providers.

Infrastructure as s Service (IaaS): This is Data Centre as a Service or remotely managed data center.
Storage as a Service: This is Disk Space as a Service or in simple terms Disk Space on Demand. You can consider this as remote storage for consumer but local for application.
Database as a Service (DaaS): This service provides consumers to access and manage persistence layer (RDBMS, Hierarchal Database – LDAP, File System, etc).
Information as a Service: This is granular business services on demand. For example tax calculation for a product/service.
Software as a Service (SaaS): This is Application as a Service. Here a major portion of or full business application is offered on demand. On the extreme of Cloud is Process as a Service (process outsourcing).
Integration as a Service: It is one of the most interesting aspects of Cloud. It provide features of traditional EAI/B2B but as service.
Platform as a Service (PaaS): This is offering provide complete SDLC of Cloud hosted application/service. Most of the matured Clouds provide this service by default.
Governance as a Service: This is basically mechanism to manage cloud computing resources, typically managing topology, resource utilization, up time, policy management and other related issues.
Testing as a Service: This is facility provides sandbox testing of developed application/service using PaaS offering.
Security as a Service: Due to open nature of internet, security is must for any offering. Security as a service may offer identity management, encryption/decryption, etc.
Friday, November 13, 2009
Case Against Private Cloud
1. Change in mindset of existing IT organization
2. Lot of automation in policy enforcement
3. Addition of one more layer of complexity in IT Infrastructure
4. Additional resource – man, machine, material (Software and hardware) requirement which my not be justified in light of RoI and TCO
5. Disruption in existing IT infrastructure
6. Shifting from private cloud to public cloud may become challenging once benefits of cloud computing are understood and internalized by IT and business.
2. Lot of automation in policy enforcement
3. Addition of one more layer of complexity in IT Infrastructure
4. Additional resource – man, machine, material (Software and hardware) requirement which my not be justified in light of RoI and TCO
5. Disruption in existing IT infrastructure
6. Shifting from private cloud to public cloud may become challenging once benefits of cloud computing are understood and internalized by IT and business.
Wednesday, November 11, 2009
Why India lags behind in Software Product development?
1. Restrictive culture which hinders free thinking
2. Limited talent pool
3. Fascination for foreign things
4. Absence of Angle investors
5. Software piracy
6. Risk aversion
7. Long gestation period
8. Most of population is in lower side of Maslow’s need pyramid
9. Easy money in body supply
10. Poor government support for globalization
2. Limited talent pool
3. Fascination for foreign things
4. Absence of Angle investors
5. Software piracy
6. Risk aversion
7. Long gestation period
8. Most of population is in lower side of Maslow’s need pyramid
9. Easy money in body supply
10. Poor government support for globalization
Tuesday, November 10, 2009
Book Review: Service - Oriented Modeling by Michael Bell
Book Review: Service - Oriented Modeling by Michael Bell: Publisher- John Wiley: ISBN- 13: 978-0-470-14111-3
Though book is published in 2008, I got the chance to real this book now. Before reading the book I had impression that this book is about SOA modeling and will be helpful in my modeling task. But its reading was quite disappointing. Book tryies to cover too many things and looses the context very frequently.
Book is highly theoretical and targeted to academics. It virtually holds no practical advice to practitioners.
The modeling part of SOA starts from chapter 8 onwards but again author looses the track very frequently.
If Michael likes to develop a language for SOA modeling he should approach some industry consortium or community so wider acceptability can be developed.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: Related information at Wikipedia: http://en.wikipedia.org/wiki/Service-oriented_modeling and at IBM http://www.ibm.com/developerworks/library/ws-soa-design1
One can get more information about book and related topics from:
1. Amazon http://www.amazon.com/Service-Oriented-Modeling-SOA-Analysis-Architecture/dp/0470141115
2. Publisher -- Wiley http://as.wiley.com/WileyCDA/WileyTitle/productCd-0470141115.html
3. Wikkipedia: http://en.wikipedia.org/wiki/Service-oriented_modeling
Though book is published in 2008, I got the chance to real this book now. Before reading the book I had impression that this book is about SOA modeling and will be helpful in my modeling task. But its reading was quite disappointing. Book tryies to cover too many things and looses the context very frequently.
Book is highly theoretical and targeted to academics. It virtually holds no practical advice to practitioners.
The modeling part of SOA starts from chapter 8 onwards but again author looses the track very frequently.
If Michael likes to develop a language for SOA modeling he should approach some industry consortium or community so wider acceptability can be developed.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: Related information at Wikipedia: http://en.wikipedia.org/wiki/Service-oriented_modeling and at IBM http://www.ibm.com/developerworks/library/ws-soa-design1
One can get more information about book and related topics from:
1. Amazon http://www.amazon.com/Service-Oriented-Modeling-SOA-Analysis-Architecture/dp/0470141115
2. Publisher -- Wiley http://as.wiley.com/WileyCDA/WileyTitle/productCd-0470141115.html
3. Wikkipedia: http://en.wikipedia.org/wiki/Service-oriented_modeling
Wednesday, November 4, 2009
Book Review: The Productive Programmer by Neal Ford
Book Review: The Productive Programmer by Neal Ford: Publisher- O’Reilly: ISBN- 13: 978-0-596-51978-0
This book is targeted to developers who must be consumer of self improvement books which lists lot of commonly identifiable day to day improvements but difficult to implement. But no doubt, book reminds lot of tips and tricks which can enhance the productivity of an average developer.
Book has divided into parts mechanics and practice which lists and identify rules of productivity and philosophy behind those rules respectively.
The first two chapters (chapter 2 and 3) talk about small tits bits of increasing productivity of an programmer using some disciple and using some tools.
Chapters 4 and 5 focus on principles automation and uniqueness.
Chapters 6 to 15 talk about some more involving practices of increasing programmers’ productivity and theoretical aspects from various walks of life.
I certainly recommend the book. It is nice read but will not keep it in my bookshelf.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: A competing book is Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin http://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882/
One can get more information about book and related topics from:
1. Book’s web presence http://productiveprogrammer.com
2. Amazon: http://www.amazon.com/Productive-Programmer-Theory-Practice-OReilly/dp/0596519788
3. Flipkart : http://www.flipkart.com/productive-programmer-neal-ford-david/0596519788-i1w3faz05d
4. Publisher – O’Reilly: http://oreilly.com/catalog/9780596519544
5. Dr. Dobbs Review: http://dobbscodetalk.com/index.php?option=com_myblog&show=The-Productive-Programmer-Book-Review.html&Itemid=29
6. leftontheweb review: http://www.leftontheweb.com/message/Book_Review_The_Productive_Programmer
7. Agile Developer Venkat's Blog review: http://www.agiledeveloper.com/blog/PermaLink.aspx?guid=f77b98ff-2865-4a27-951c-bf51bd159468
8. Library Thing review: http://www.librarything.com/work/5606442
9. Mark Needham review: http://www.markhneedham.com/blog/2008/09/05/the-productive-programmer-book-review/
10. DevSource review: http://www.devsource.com/c/a/Architecture/Book-Review-The-Productive-Programmer-by-Neal-Ford/
This book is targeted to developers who must be consumer of self improvement books which lists lot of commonly identifiable day to day improvements but difficult to implement. But no doubt, book reminds lot of tips and tricks which can enhance the productivity of an average developer.
Book has divided into parts mechanics and practice which lists and identify rules of productivity and philosophy behind those rules respectively.
The first two chapters (chapter 2 and 3) talk about small tits bits of increasing productivity of an programmer using some disciple and using some tools.
Chapters 4 and 5 focus on principles automation and uniqueness.
Chapters 6 to 15 talk about some more involving practices of increasing programmers’ productivity and theoretical aspects from various walks of life.
I certainly recommend the book. It is nice read but will not keep it in my bookshelf.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: A competing book is Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin http://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882/
One can get more information about book and related topics from:
1. Book’s web presence http://productiveprogrammer.com
2. Amazon: http://www.amazon.com/Productive-Programmer-Theory-Practice-OReilly/dp/0596519788
3. Flipkart : http://www.flipkart.com/productive-programmer-neal-ford-david/0596519788-i1w3faz05d
4. Publisher – O’Reilly: http://oreilly.com/catalog/9780596519544
5. Dr. Dobbs Review: http://dobbscodetalk.com/index.php?option=com_myblog&show=The-Productive-Programmer-Book-Review.html&Itemid=29
6. leftontheweb review: http://www.leftontheweb.com/message/Book_Review_The_Productive_Programmer
7. Agile Developer Venkat's Blog review: http://www.agiledeveloper.com/blog/PermaLink.aspx?guid=f77b98ff-2865-4a27-951c-bf51bd159468
8. Library Thing review: http://www.librarything.com/work/5606442
9. Mark Needham review: http://www.markhneedham.com/blog/2008/09/05/the-productive-programmer-book-review/
10. DevSource review: http://www.devsource.com/c/a/Architecture/Book-Review-The-Productive-Programmer-by-Neal-Ford/
Tuesday, November 3, 2009
Virtualization Explained
Virtualization represents any type of process obfuscation where a process is removed from its physical operating environment.
Because of this broad definition, virtualization can almost be applied to any and all parts of IT assets. For example, mobile device emulators are a form of virtualization because the hardware platform normally required to run the mobile operating system has been emulated, removing the OS binding from the hardware it was written for.
But for the real life perspective virtualization can be classified as:
Operating System Virtualization
This is the most prevalent form of virtualization because of the need of running multiple operating systems on a single hardware.
In this form of virtualization, Virtual Machine Managers (VMMs) manage each virtual machine individually on a host operating system (some time directly on hardware). In turn each Virtual Machine hosts a separate instance of operating system. Each of these separate operating systems instances is unaware of the other.
Application Server Virtualization
Application Server Virtualization is just glamorous name of advance load balancing specifically of reverse proxy.
This is an example of one-to-many virtualization: one server is presented to the world, hiding the availability of multiple servers behind a reverse proxy.
Application Virtualization
Application virtualization can be of three types. One way is using Thin Client – browser based access to application. The second one is Zero Client – remote access of machine which hosts application via remote access mechanism. The third approach involves mechanism where application is hosted at remote machine but is executed locally.
Hardware Virtualization
Hardware virtualization has roots in parallel processing. With advent of multi processing hardware and multi core processor it has become omni present in business.
Hardware virtualization breaks up pieces and locations of physical hardware into independent segments and manages those segments as separate, individual components.
Storage Virtualization
Storage virtualization can be broken up into two general types: block virtualization and file virtualization.
Block virtualization is best summed up by Storage Area Network (SAN) and Network Attached Storage (NAS) technologies: distributed storage networks that appear to be single physical devices.
File virtualization moves the virtual layer up into the more human-consumable file and directory structure level. Most file virtualization technologies sit in front of storage networks and keep track of which files and directories reside on which storage devices, maintaining global mappings of file locations.
Service Virtualization
Service virtualization is like catch all case for all of the above definitions. Service virtualization connects all of the components utilized in delivering a service over the network.
In SOA service virtualization is confined to software aspect only is primarily achieved using ESB.
Because of this broad definition, virtualization can almost be applied to any and all parts of IT assets. For example, mobile device emulators are a form of virtualization because the hardware platform normally required to run the mobile operating system has been emulated, removing the OS binding from the hardware it was written for.
But for the real life perspective virtualization can be classified as:
Operating System Virtualization
This is the most prevalent form of virtualization because of the need of running multiple operating systems on a single hardware.
In this form of virtualization, Virtual Machine Managers (VMMs) manage each virtual machine individually on a host operating system (some time directly on hardware). In turn each Virtual Machine hosts a separate instance of operating system. Each of these separate operating systems instances is unaware of the other.
Application Server Virtualization
Application Server Virtualization is just glamorous name of advance load balancing specifically of reverse proxy.
This is an example of one-to-many virtualization: one server is presented to the world, hiding the availability of multiple servers behind a reverse proxy.
Application Virtualization
Application virtualization can be of three types. One way is using Thin Client – browser based access to application. The second one is Zero Client – remote access of machine which hosts application via remote access mechanism. The third approach involves mechanism where application is hosted at remote machine but is executed locally.
Hardware Virtualization
Hardware virtualization has roots in parallel processing. With advent of multi processing hardware and multi core processor it has become omni present in business.
Hardware virtualization breaks up pieces and locations of physical hardware into independent segments and manages those segments as separate, individual components.
Storage Virtualization
Storage virtualization can be broken up into two general types: block virtualization and file virtualization.
Block virtualization is best summed up by Storage Area Network (SAN) and Network Attached Storage (NAS) technologies: distributed storage networks that appear to be single physical devices.
File virtualization moves the virtual layer up into the more human-consumable file and directory structure level. Most file virtualization technologies sit in front of storage networks and keep track of which files and directories reside on which storage devices, maintaining global mappings of file locations.
Service Virtualization
Service virtualization is like catch all case for all of the above definitions. Service virtualization connects all of the components utilized in delivering a service over the network.
In SOA service virtualization is confined to software aspect only is primarily achieved using ESB.
Monday, November 2, 2009
SOA Reference Architecture Traits
A SOA Reference Architecture must exhibit following traits:
1. Separation and Abstraction: Different functionalities of architecture must be sufficiently abstracted and separated (may be as layers) to incorporate functional and technological challenges under given business scenario.
2. Options: Reference architecture must give multiple options to carry out a process/task/activity to leverage the abstraction and separation of layers. It also enables one to carry out implementation to optimize as per the underlying platform and tool usage.
3. Architectural Decisions: Reference Architecture must support non functional requirements which in turn require grading of KPI ( Key Performance Indicator) and SLA ( Service Level Agreements).
4. Enabling Technology: Reference Architecture should be mapped to real life, available platforms, tools and techniques. At this point architecture may show some rigidity due to constrains of chosen platform/tools/ techniques.
1. Separation and Abstraction: Different functionalities of architecture must be sufficiently abstracted and separated (may be as layers) to incorporate functional and technological challenges under given business scenario.
2. Options: Reference architecture must give multiple options to carry out a process/task/activity to leverage the abstraction and separation of layers. It also enables one to carry out implementation to optimize as per the underlying platform and tool usage.
3. Architectural Decisions: Reference Architecture must support non functional requirements which in turn require grading of KPI ( Key Performance Indicator) and SLA ( Service Level Agreements).
4. Enabling Technology: Reference Architecture should be mapped to real life, available platforms, tools and techniques. At this point architecture may show some rigidity due to constrains of chosen platform/tools/ techniques.
Wednesday, October 21, 2009
Book Review: Masterminds of Programming
Book Review: Masterminds of Programming Edited by Federico Biancuzzi and Shane Warden: Publisher- O’Reilly: ISBN- 13: 978-0-596-51517-1
As the name of the book suggest, this book contains interviews with software legendary personalities who has put good part of their career in development of computer languages.
As expected book does not contain any technical details but gives insight of design philosophies of the different languages. It also exposes some of the legendary personalities as normal humans – full of faults.
I specially like interview with Don Chamberlin who talks in details of SQL design philosophy. Talk with Thomas Kurtz depicts determinism of him to maintain BASIC.
Do not expect too much from this book but it is good aeroplane read.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
One can get more information about book and related topics from:
1. Amazon: http://www.amazon.com/Masterminds-Programming-Conversations-Creators-Languages/dp/0596515170
2. Publisher – O’Reilly http://oreilly.com/catalog/9780596515171
3. Flipkart: http://www.flipkart.com/masterminds-programming-federico-biancuzzi-shane/8184047029-aw23fqz0oc
4. One More Review: http://www.flipkart.com/masterminds-programming-federico-biancuzzi-shane/8184047029-aw23fqz0oc
As the name of the book suggest, this book contains interviews with software legendary personalities who has put good part of their career in development of computer languages.
As expected book does not contain any technical details but gives insight of design philosophies of the different languages. It also exposes some of the legendary personalities as normal humans – full of faults.
I specially like interview with Don Chamberlin who talks in details of SQL design philosophy. Talk with Thomas Kurtz depicts determinism of him to maintain BASIC.
Do not expect too much from this book but it is good aeroplane read.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
One can get more information about book and related topics from:
1. Amazon: http://www.amazon.com/Masterminds-Programming-Conversations-Creators-Languages/dp/0596515170
2. Publisher – O’Reilly http://oreilly.com/catalog/9780596515171
3. Flipkart: http://www.flipkart.com/masterminds-programming-federico-biancuzzi-shane/8184047029-aw23fqz0oc
4. One More Review: http://www.flipkart.com/masterminds-programming-federico-biancuzzi-shane/8184047029-aw23fqz0oc
Monday, October 19, 2009
Wednesday, October 14, 2009
Monday, October 12, 2009
Book Review: Successful Service Design for Telecommunications - A comprehensive guide to design and implementation
Book Review: Successful Service Design for Telecommunications - A comprehensive guide to design and implementation: Publisher- Wiley: ISBN- 13: 978-0-470-75393-4
During course of designing a Telecom/ISP product architecture and design product, I encountered Successful Service Design for Telecommunications – A comprehensive guide to design and implementation by Sauming Pang. Before starting the book my impression was that this book will talk about details of Telecom specific service design and implementation. But After reading the book I realized that this book is not confined to Telecom vertical. The principles outlined in this book are universally applicable across industry vertical.
Though book does not mention any of the frameworks but it seems that book is highly influenced by USBOK .
The book is divided into twelve chapters which very clearly depict considerations of design and implementation. The book not only covers technical considerations but also business which are generally overlooked by technical folks.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: A complementary book is Telecom Management Crash Course : A Telecom Company Survival Guide (Crash Course) by P.J Louis http://www.amazon.com/Telecom-Management-Crash-Course-Survival/dp/0071386203
One can get more information about book and related topics from:
1. Amazon: http://www.amazon.com/Successful-Service-Design-Telecommunications-implementation/dp/0470753935
2. Publisher -- Wiley http://as.wiley.com/WileyCDA/WileyTitle/productCd-0470753935.html
3. Purchase at Flipkart: http://www.flipkart.com/successful-service-design-telecommunications-sauming/0470753935-0xw3f9w0fq
4. Purchase at A1Books: http://www.a1books.co.in/searchdetail.do?a1Code=booksgoogle&itemCode=0470753935
During course of designing a Telecom/ISP product architecture and design product, I encountered Successful Service Design for Telecommunications – A comprehensive guide to design and implementation by Sauming Pang. Before starting the book my impression was that this book will talk about details of Telecom specific service design and implementation. But After reading the book I realized that this book is not confined to Telecom vertical. The principles outlined in this book are universally applicable across industry vertical.
Though book does not mention any of the frameworks but it seems that book is highly influenced by USBOK .
The book is divided into twelve chapters which very clearly depict considerations of design and implementation. The book not only covers technical considerations but also business which are generally overlooked by technical folks.
Disclaimer: I did not get paid to review this book, and I do not stand to gain anything if you buy the book. I have no relationship with the publisher or the author.
Further reading: A complementary book is Telecom Management Crash Course : A Telecom Company Survival Guide (Crash Course) by P.J Louis http://www.amazon.com/Telecom-Management-Crash-Course-Survival/dp/0071386203
One can get more information about book and related topics from:
1. Amazon: http://www.amazon.com/Successful-Service-Design-Telecommunications-implementation/dp/0470753935
2. Publisher -- Wiley http://as.wiley.com/WileyCDA/WileyTitle/productCd-0470753935.html
3. Purchase at Flipkart: http://www.flipkart.com/successful-service-design-telecommunications-sauming/0470753935-0xw3f9w0fq
4. Purchase at A1Books: http://www.a1books.co.in/searchdetail.do?a1Code=booksgoogle&itemCode=0470753935
Thursday, October 8, 2009
EAI & SOA Development & Maintenance: Centralized or Distributed
Centralized Development & Maintenance
1. Knowledge is at one place, difficult to assemble but once accumulated easy to manage
2. EAI and SOA workforce needs exposure to respective systems under lens and specialized knowledge about EAI &/or SOA. In case of centralized development effort manpower can be channelized in effective way and team members develop cross application skills.
3. Better architectural control
4. Better design time security due to centralized policy enforcement.
5. It need more coordination on part of EAI/SOA team but reusability of services will offset that.
Distributed Development & Maintenance
1. Knowledge is distributed across islands of applications, so difficult to manage
2. Cross application skills are not developed but application specific specialists get developed with little exposure to EAI or/& SOA.
3. EAI Workforce may not be utilized if EAI/SOA work is not in sufficient quantity.
4. In distributed development environment, EAI/SOA may loose focus and deviate from Enterprise architecture which may:
a. Jeopardize BPM initiative at later stage;
b. Duplication of services/functionality
5. Increased cost of maintaining and establishing development environment
6. Governance issues may crop up, like ownership of services
7. Difficult to enforce security policies
1. Knowledge is at one place, difficult to assemble but once accumulated easy to manage
2. EAI and SOA workforce needs exposure to respective systems under lens and specialized knowledge about EAI &/or SOA. In case of centralized development effort manpower can be channelized in effective way and team members develop cross application skills.
3. Better architectural control
4. Better design time security due to centralized policy enforcement.
5. It need more coordination on part of EAI/SOA team but reusability of services will offset that.
Distributed Development & Maintenance
1. Knowledge is distributed across islands of applications, so difficult to manage
2. Cross application skills are not developed but application specific specialists get developed with little exposure to EAI or/& SOA.
3. EAI Workforce may not be utilized if EAI/SOA work is not in sufficient quantity.
4. In distributed development environment, EAI/SOA may loose focus and deviate from Enterprise architecture which may:
a. Jeopardize BPM initiative at later stage;
b. Duplication of services/functionality
5. Increased cost of maintaining and establishing development environment
6. Governance issues may crop up, like ownership of services
7. Difficult to enforce security policies
Wednesday, October 7, 2009
Tuesday, October 6, 2009
Sunday, October 4, 2009
IT and Business: A reality check
The conflict in business and IT is a well known fact but least talked subject. Folks at IT side – IT Service providers, product vendors and IT departments always have view that business folks do not understand technology and put unreasonable demands. Some what similar complaints Business folks have with IT folks. IT folks do not understand Business and only think in terms of technology. SOA tries to bridge this gap but again it assumes that both warring sides understand each other.
To depict the picture, I have developed three scenarios. These scenarios are based on famous Theory X, Theory Y by McGregor and Theory Z.
Theory B depicts the world seen by Business folks.

Theory I depicts the world seen by IT folks.

Both Theory B and I depicts the worlds in very biased fashion. The reality resides some where in between which is depicted using Theory R.

To depict the picture, I have developed three scenarios. These scenarios are based on famous Theory X, Theory Y by McGregor and Theory Z.
Theory B depicts the world seen by Business folks.

Theory I depicts the world seen by IT folks.

Both Theory B and I depicts the worlds in very biased fashion. The reality resides some where in between which is depicted using Theory R.

Friday, September 18, 2009
Services vs. Components
Services are mistaken as components. This post emphasizes the difference between services and components.
1. Components are the concrete form which realizes service.

2. Components can be reused in two ways:
a. Binary reuse
b. As distributed object
While service reuse is only through composition.
1. Components are the concrete form which realizes service.

2. Components can be reused in two ways:
a. Binary reuse
b. As distributed object
While service reuse is only through composition.
Thursday, September 17, 2009
Services vs. Distributed Objects
Even after fairly large implementations of web services and wide spread adoption of services, services still compared with distributed objects. This entry is dedicated to highlight differences between services and distributed objects.
1. Distributed objects are designed to operate in corporate intranet environment while services are for internet.
2. Distributed objects boasts object’s life cycle which can be summarized as:
a. Upon request, a factory instantiates the object;
b. The consumer who requested the instantiation performs operations on the object instance; and
c. Later, either the consumer releases the instance or the runtime system garbage-collects it.
A special case is the singleton object, which does not go through this cycle. In both the cases, the object is identified through a reference that can be passed between processes to provide a access mechanism for it. Objects often contain references to other objects, and distributed object technology comes with exhaustive reference-handling techniques to manage objects’ lifecycle.
Service does not feature object like lifecycle, factory, garbage collection, etc.
3. The flow of information among distributed objects is very closed and only understood by objects of same type (say RMI, DCOM, CORBA, etc). But in services information exchange is done using XML or some derivative of XML.
1. Distributed objects are designed to operate in corporate intranet environment while services are for internet.
2. Distributed objects boasts object’s life cycle which can be summarized as:
a. Upon request, a factory instantiates the object;
b. The consumer who requested the instantiation performs operations on the object instance; and
c. Later, either the consumer releases the instance or the runtime system garbage-collects it.
A special case is the singleton object, which does not go through this cycle. In both the cases, the object is identified through a reference that can be passed between processes to provide a access mechanism for it. Objects often contain references to other objects, and distributed object technology comes with exhaustive reference-handling techniques to manage objects’ lifecycle.
Service does not feature object like lifecycle, factory, garbage collection, etc.
3. The flow of information among distributed objects is very closed and only understood by objects of same type (say RMI, DCOM, CORBA, etc). But in services information exchange is done using XML or some derivative of XML.
Service vs. Process
The services in any SOA ecosystem must demonstrate following traits:
• Compose-ability
• Statelessness
• Context unawareness
• Discoverability over network
• Reusability
• Decoupling of service implementation and contract/interface
• Adherence to standards
The driver of SOA ecosystem is creating application with fast pace. This driver is achieved exploiting above mentioned traits. With maturity, process also exposed as services to realize bigger and complex processes. This usage forces exposed processes to loose statelessness, context unawareness with varying degree. Now the dilemma creeps in, is architecture deviating from basic tenants of service design.
• Compose-ability
• Statelessness
• Context unawareness
• Discoverability over network
• Reusability
• Decoupling of service implementation and contract/interface
• Adherence to standards
The driver of SOA ecosystem is creating application with fast pace. This driver is achieved exploiting above mentioned traits. With maturity, process also exposed as services to realize bigger and complex processes. This usage forces exposed processes to loose statelessness, context unawareness with varying degree. Now the dilemma creeps in, is architecture deviating from basic tenants of service design.
Wednesday, September 16, 2009
Service Design Principles
Service is a computational functionality exposed over network. So any computational resource which can expose its functionality over network can be treated as service. But do we need such type of services in SOA ecosystem. Definitely NOT. In SOA ecosystem, service must demonstrate some traits:
• Compose-ability
• Statelessness
• Context unawareness
• Discoverability over network
• Reusability
• Decoupling of service implementation and contract/interface
• Adherence to standards
To make sure that a service demonstrates outlined traits, following design principles must be followed while designing a service in any SOA ecosystem.
1. Standard Service Contract/Interface
2. Optimal Service Granularity
3. Service Re-usability
4. Stateless Service
5. Context Unaware Service
6. Compose-ability of Service
7. Service discover-ability
8. Service Autonomy
9. Service context abstraction
10. Externalization of non core aspects
11. Service versioning
12. Multi contract/interface availability
13. Idempotent Service
14. Coupling Management
1. Standard Service Contract/Interface: Service in a defined inventory must have standardized contract for availing the intended business functionality. Standardization keeps needs of data transformation minimal and also brings in predictability and increases comfort level of calling party.
2. Optimum Service Granularity: Service granularity is one of the joint decisions of Business and Technical teams with respect to service design. On the basis of granularity services can be classified as:
a. Atomic: Service which can enforce transaction related features to its exposed operations.
b. Molecular: Services which can not enforce transaction related features but can have compensatory features. This type of services is composition of underlying atomic and molecular services. Some time it is very difficult to differentiate between a molecular service and a process because process can also be exposed as service.
3. Service Re-usability: Service re-usability is one of the driving forces of SOA ecosystem. Service re-usability is function of granularity, contract/interface standardization, compose ability, context abstraction, idempotent nature, context unawareness and versioning. In SOA ecosystem, re-usability of service is big driver of molecular composite service.
4. Stateless Service: In a SOA ecosystem, services must be stateless whether atomic or molecular. Stateless of service facilitates compose-ability. But as service moves from pure service to process keeping statelessness become difficult but it is always desirable.
a. Current result of service execution must not be affect by any of previous result.
5. Context Unaware Service: Context unawareness of a service is contributing factor for statelessness. Context unawareness essentially about two main concepts:
a. Who is calling? (may be negated in serving versioning, testing/training mode)
b. Who is called me earlier? ( Make sure that service behavior must not change depending upon previous calling party)
6. Compose-ability of Service: for an SOA ecosystem, one of the important metric is number of services reused. This reuse of service may be of three types:
a. Consuming a service in an application
b. Consuming a service in process
c. Consuming a service in creation of another service
Last two type of service consumption is mainly result of compose-ability of a service.
While designing a service pay attention to following aspects:
a. Ability to compose other services
b. Ability of to be composed
c. How deep composition should be?
7. Service Discover-ability: In a SOA ecosystem, service are discovered in following manner:
Consumer discovers a provider at design time:
i. Developer/Designer refer some list manually
ii. IDE presents pre-listed ( with IDE or pre-configured Registry)
d. Consumer discovers a provider at run time:
i. Consumer discovers a provider while looking at repository where provider is listed. This process happens at first call to provider. Discovery process gets repeated if consumer lost the information about provider. Discovery process also happens if provider becomes unavailable.
ii. Consumer discovers provider with each call via trip to repository.
Each discovery scheme has its own pro and cons. Most of the time discover-ability of service is not only function of service interface/contract design but also infrastructure capability of SOA ecosystem.
8. Service Autonomy: For any atomic service, the implementation is in some component and some persistence layer to hold data. In spirit of component re-usability, one can reuse components in two or more services. This reuse of components can be of two types:
a. Different installations of same component ( different binaries) are utilized
b. Same installation of a component is used in two or more services
At persistence layer services can again utilize one or multiple instances of same data. While deciding what type of persistence layer is shared also raises difficult question of integration (EAI).
In Molecular services, services composed also constitute big role while deciding Service autonomy.
9. Service context abstraction: Service context abstraction idea is borrowed from encapsulation of object oriented world. In Bjarne Stroustrup's words - expose minimal but complete. On the lighter side “Exposed contract/interface is like Bikini. What does it reveal is sufficient to arouse, but what it conceals is vital”. The service contract/interface should consider exposing following aspects:
a. Functional aspects
b. Technical aspects
c. Non Functional and non technical ( abilities) aspects
10. Externalization of non core aspects: In any good software design non core aspects of that software must be externalize to keep focus on business logic and keeping the code simple. The concept of externalization can also be understood from Aspect Oriented Programming perspective.
If we move into conventional software design, following considerations must be in mind:
a. Configuration parameters ( generally technical attributes)
b. Rules ( generally business rules/attributes)
c. Hot deploy-able vs. non hot deploy-able
d. Design time vs. run-time change in attributes.
11. Service versioning: Service must be able to support versioning to cater its evolution. The versioning support for a service level can be handled at platform level or at service level or at deployment level. All schemes of versioning support have their own pros and cons.
While catering for service versioning need, pay attention to:
a. Context unawareness of service
b. Multi version contract/interface
c. Multi version deployment of service
12. Multi contract/interface availability: In some cases, especially when SHE (Service Hosting) is not used, service is made available at multiple channels. If this is the need then pays attention to availability of multi channel interface/contract.
13. Idempotent Service: If service to be called by same consumer, its response must not be affected in any way. This is one of the important design aspect while realizing context unawareness and statelessness.
14. Coupling Management: In any software system one of the important goals is reduced coupling. But in real life coupling can not reach to zero it can be minimized or transferred from one face to another. In SOA ecosystem, coupling with respect to service can be understood as:
a. Semantic coupling: Coupling between consumer and producer with respect to data structure passed while service is called for consumption.
b. Ontological coupling: Coupling between consumer and producer with respect to nomenclature of service operation/method/function.
c. Temporal Coupling: Coupling between consumer and producer with respect to time and calling sequence.
d. Spatial Coupling: Coupling between consumer and producer with respect to address and addressing scheme
e. Stamp Coupling: Where two services modify common data.
• Compose-ability
• Statelessness
• Context unawareness
• Discoverability over network
• Reusability
• Decoupling of service implementation and contract/interface
• Adherence to standards
To make sure that a service demonstrates outlined traits, following design principles must be followed while designing a service in any SOA ecosystem.
1. Standard Service Contract/Interface
2. Optimal Service Granularity
3. Service Re-usability
4. Stateless Service
5. Context Unaware Service
6. Compose-ability of Service
7. Service discover-ability
8. Service Autonomy
9. Service context abstraction
10. Externalization of non core aspects
11. Service versioning
12. Multi contract/interface availability
13. Idempotent Service
14. Coupling Management
1. Standard Service Contract/Interface: Service in a defined inventory must have standardized contract for availing the intended business functionality. Standardization keeps needs of data transformation minimal and also brings in predictability and increases comfort level of calling party.
2. Optimum Service Granularity: Service granularity is one of the joint decisions of Business and Technical teams with respect to service design. On the basis of granularity services can be classified as:
a. Atomic: Service which can enforce transaction related features to its exposed operations.
b. Molecular: Services which can not enforce transaction related features but can have compensatory features. This type of services is composition of underlying atomic and molecular services. Some time it is very difficult to differentiate between a molecular service and a process because process can also be exposed as service.
3. Service Re-usability: Service re-usability is one of the driving forces of SOA ecosystem. Service re-usability is function of granularity, contract/interface standardization, compose ability, context abstraction, idempotent nature, context unawareness and versioning. In SOA ecosystem, re-usability of service is big driver of molecular composite service.
4. Stateless Service: In a SOA ecosystem, services must be stateless whether atomic or molecular. Stateless of service facilitates compose-ability. But as service moves from pure service to process keeping statelessness become difficult but it is always desirable.
a. Current result of service execution must not be affect by any of previous result.
5. Context Unaware Service: Context unawareness of a service is contributing factor for statelessness. Context unawareness essentially about two main concepts:
a. Who is calling? (may be negated in serving versioning, testing/training mode)
b. Who is called me earlier? ( Make sure that service behavior must not change depending upon previous calling party)
6. Compose-ability of Service: for an SOA ecosystem, one of the important metric is number of services reused. This reuse of service may be of three types:
a. Consuming a service in an application
b. Consuming a service in process
c. Consuming a service in creation of another service
Last two type of service consumption is mainly result of compose-ability of a service.
While designing a service pay attention to following aspects:
a. Ability to compose other services
b. Ability of to be composed
c. How deep composition should be?
7. Service Discover-ability: In a SOA ecosystem, service are discovered in following manner:
Consumer discovers a provider at design time:
i. Developer/Designer refer some list manually
ii. IDE presents pre-listed ( with IDE or pre-configured Registry)
d. Consumer discovers a provider at run time:
i. Consumer discovers a provider while looking at repository where provider is listed. This process happens at first call to provider. Discovery process gets repeated if consumer lost the information about provider. Discovery process also happens if provider becomes unavailable.
ii. Consumer discovers provider with each call via trip to repository.
Each discovery scheme has its own pro and cons. Most of the time discover-ability of service is not only function of service interface/contract design but also infrastructure capability of SOA ecosystem.
8. Service Autonomy: For any atomic service, the implementation is in some component and some persistence layer to hold data. In spirit of component re-usability, one can reuse components in two or more services. This reuse of components can be of two types:
a. Different installations of same component ( different binaries) are utilized
b. Same installation of a component is used in two or more services
At persistence layer services can again utilize one or multiple instances of same data. While deciding what type of persistence layer is shared also raises difficult question of integration (EAI).
In Molecular services, services composed also constitute big role while deciding Service autonomy.
9. Service context abstraction: Service context abstraction idea is borrowed from encapsulation of object oriented world. In Bjarne Stroustrup's words - expose minimal but complete. On the lighter side “Exposed contract/interface is like Bikini. What does it reveal is sufficient to arouse, but what it conceals is vital”. The service contract/interface should consider exposing following aspects:
a. Functional aspects
b. Technical aspects
c. Non Functional and non technical ( abilities) aspects
10. Externalization of non core aspects: In any good software design non core aspects of that software must be externalize to keep focus on business logic and keeping the code simple. The concept of externalization can also be understood from Aspect Oriented Programming perspective.
If we move into conventional software design, following considerations must be in mind:
a. Configuration parameters ( generally technical attributes)
b. Rules ( generally business rules/attributes)
c. Hot deploy-able vs. non hot deploy-able
d. Design time vs. run-time change in attributes.
11. Service versioning: Service must be able to support versioning to cater its evolution. The versioning support for a service level can be handled at platform level or at service level or at deployment level. All schemes of versioning support have their own pros and cons.
While catering for service versioning need, pay attention to:
a. Context unawareness of service
b. Multi version contract/interface
c. Multi version deployment of service
12. Multi contract/interface availability: In some cases, especially when SHE (Service Hosting) is not used, service is made available at multiple channels. If this is the need then pays attention to availability of multi channel interface/contract.
13. Idempotent Service: If service to be called by same consumer, its response must not be affected in any way. This is one of the important design aspect while realizing context unawareness and statelessness.
14. Coupling Management: In any software system one of the important goals is reduced coupling. But in real life coupling can not reach to zero it can be minimized or transferred from one face to another. In SOA ecosystem, coupling with respect to service can be understood as:
a. Semantic coupling: Coupling between consumer and producer with respect to data structure passed while service is called for consumption.
b. Ontological coupling: Coupling between consumer and producer with respect to nomenclature of service operation/method/function.
c. Temporal Coupling: Coupling between consumer and producer with respect to time and calling sequence.
d. Spatial Coupling: Coupling between consumer and producer with respect to address and addressing scheme
e. Stamp Coupling: Where two services modify common data.
Saturday, September 12, 2009
Friday, September 11, 2009
Thursday, September 10, 2009
Friday, September 4, 2009
Services Elements
In any enterprise class SOA implementation, services form back bone. To understand SOA, back bone has to be understood in comprehensive manner. To simplify the understanding of SOA, I have tried classifying elements of services in Business and Technical categories.



Thursday, September 3, 2009
SOA Deployment Challenges
The challenges of deploying SOA can be categorized as: technical and operational.
Major technical challenges are:
• Debugging and tracing
• Efficient caching of requests and sessions
• Security, monitoring and notification
• Compliance with multiple computing standards
• Support for internal and external clients with different needs
• Quality of service and management of service-level agreements
• Availability and scalability
• Decomposition of existing applications and migration of legacy services
Major operational challenges are:
• Version control
• Learning curve for deployers
• Effects on existing operational tools and environments
• Pressures for timely releases
• Governance, especially in the face of constant changes
• Consistency in development, test and prod environments
Resolving the challenges is an ongoing battle. These challenges can be faced with the help of following:
• Lightweight, composite, layered and high-performance SOA platform
• A unified testing framework
• Decomposition of model-driven services
• An extensive authentication and authorization process for security ( such as eXtensible Access Control Markup Language (XACML)-based)
• A strong yet flexible governance process through a service registry and repository
• Business rules are in Rule engine
• Robust forensic (monitoring, audit, logging and notification) framework
• Change management for dependencies and backward compatibility
Major technical challenges are:
• Debugging and tracing
• Efficient caching of requests and sessions
• Security, monitoring and notification
• Compliance with multiple computing standards
• Support for internal and external clients with different needs
• Quality of service and management of service-level agreements
• Availability and scalability
• Decomposition of existing applications and migration of legacy services
Major operational challenges are:
• Version control
• Learning curve for deployers
• Effects on existing operational tools and environments
• Pressures for timely releases
• Governance, especially in the face of constant changes
• Consistency in development, test and prod environments
Resolving the challenges is an ongoing battle. These challenges can be faced with the help of following:
• Lightweight, composite, layered and high-performance SOA platform
• A unified testing framework
• Decomposition of model-driven services
• An extensive authentication and authorization process for security ( such as eXtensible Access Control Markup Language (XACML)-based)
• A strong yet flexible governance process through a service registry and repository
• Business rules are in Rule engine
• Robust forensic (monitoring, audit, logging and notification) framework
• Change management for dependencies and backward compatibility
Wednesday, August 19, 2009
Build, Buy or Reuse: Services
The one of the most flaunted benefit of SOA is reuse of services. But it is one of the least used aspects of SOA. But Why so?
In enterprises there is no framework exist which can evaluate a service/service requirement which help in reach a decision of Build, Buy or Reuse. To fill up this gap, I have developed a framework. This framework has three aspects:
1. Appraisal Structure
2. Evaluation Criteria
3. Influencers
Appraisal Structure
The Appraisal Structure offers a classification for the types of considerations within the context of the business. The considerations and decision to build, buy or reuse fall into the following categories:
a. Strategic
b. Tactical
c. Operational
d. Business
e. Technical
Strategic considerations deal with the long-term vision and direction of an enterprise. These include:
• Market Share and Differentiation
• Growth
• Strategic Change Management
Tactical considerations deal with the short-term decisions and direction of an enterprise. These include:
• Current Project Portfolio
• Cash flow considerations
• Time consumption considerations
Operational considerations deal with the operational aspects of a project or a portfolio of enterprise. These include:
• Governance
• Change Management
• Skills
• Support and Maintenance
The business considerations are the ones that support the short- to medium-term objectives of the business. These include:
• Contract Management
• Depreciating of Assets
• Internal or External Provision
Enterprise have a technical strategy—one that states what technologies can be used and for what purposes. Considerations in this category include:
• Technology Considerations
• Technology Choice
• Interoperability/Integration
• Repository of Assets
Evaluation Criteria
There are eight Evaluation criteria identified eight attributes that affect Build, Buy or Reuse decision of services.
• Delivery Time
• Complexity
• Investment
• Expense
• Maturity
• Requirements compromise/match
• Maintenance
• Support

Influencers
There are five influencers. Each influencer has attractive and repulsive force field. Which force field will be more effective depends upon particular scenario – internal and external environmental conditions.
• Investment: It has one of the strongest force field – attraction as well as repulsive. This influencer has numerous aspects such as remaining cost-neutral RoI, profitability, affordability, and finally the cost implications of not doing it.
• Expenses: This influencer affect any decision on continuous basis. Investment and expenses in combination cover financial aspect of Build, Buy or Reuse decision. Like Investment, Expense also has multiple views – Cash Flow, ToC, etc.
• Quality: In market one with right quality wins keeping other parameters constant. Therefore Quality of Service (QoS) plays major role while making Build, Buy or Reuse decision. This influencer is also multi facet. Most of the abilities or non functional requirements are covered under Quality head.
• Time: In fast changing environment time is very critical. Time to market is one of the important parameter which affects Build, Buy or Reuse decision.
• Sustainability: Due to fast pace of technological and business environment evolution, obsolesce of a particular service and effort needed to keep it updated drives Build, Buy or Reuse decision.
The framework is very general in nature. It must be tweaked to a particular enterprise business environment, vision, goal, objectives and tactical needs.
Reference: The Architectural Journal (Microsoft) 20
In enterprises there is no framework exist which can evaluate a service/service requirement which help in reach a decision of Build, Buy or Reuse. To fill up this gap, I have developed a framework. This framework has three aspects:
1. Appraisal Structure
2. Evaluation Criteria
3. Influencers
Appraisal Structure
The Appraisal Structure offers a classification for the types of considerations within the context of the business. The considerations and decision to build, buy or reuse fall into the following categories:
a. Strategic
b. Tactical
c. Operational
d. Business
e. Technical
Strategic considerations deal with the long-term vision and direction of an enterprise. These include:
• Market Share and Differentiation
• Growth
• Strategic Change Management
Tactical considerations deal with the short-term decisions and direction of an enterprise. These include:
• Current Project Portfolio
• Cash flow considerations
• Time consumption considerations
Operational considerations deal with the operational aspects of a project or a portfolio of enterprise. These include:
• Governance
• Change Management
• Skills
• Support and Maintenance
The business considerations are the ones that support the short- to medium-term objectives of the business. These include:
• Contract Management
• Depreciating of Assets
• Internal or External Provision
Enterprise have a technical strategy—one that states what technologies can be used and for what purposes. Considerations in this category include:
• Technology Considerations
• Technology Choice
• Interoperability/Integration
• Repository of Assets
Evaluation Criteria
There are eight Evaluation criteria identified eight attributes that affect Build, Buy or Reuse decision of services.
• Delivery Time
• Complexity
• Investment
• Expense
• Maturity
• Requirements compromise/match
• Maintenance
• Support

Influencers
There are five influencers. Each influencer has attractive and repulsive force field. Which force field will be more effective depends upon particular scenario – internal and external environmental conditions.
• Investment: It has one of the strongest force field – attraction as well as repulsive. This influencer has numerous aspects such as remaining cost-neutral RoI, profitability, affordability, and finally the cost implications of not doing it.
• Expenses: This influencer affect any decision on continuous basis. Investment and expenses in combination cover financial aspect of Build, Buy or Reuse decision. Like Investment, Expense also has multiple views – Cash Flow, ToC, etc.
• Quality: In market one with right quality wins keeping other parameters constant. Therefore Quality of Service (QoS) plays major role while making Build, Buy or Reuse decision. This influencer is also multi facet. Most of the abilities or non functional requirements are covered under Quality head.
• Time: In fast changing environment time is very critical. Time to market is one of the important parameter which affects Build, Buy or Reuse decision.
• Sustainability: Due to fast pace of technological and business environment evolution, obsolesce of a particular service and effort needed to keep it updated drives Build, Buy or Reuse decision.
The framework is very general in nature. It must be tweaked to a particular enterprise business environment, vision, goal, objectives and tactical needs.
Reference: The Architectural Journal (Microsoft) 20
Friday, August 14, 2009
Top 16 lessons from Real world BPM Projects
DO
• Start with an low hanging fruits – easy to implement, least politicized
• Document the process in detail
• Establish a simple ROI metric for initiative that is meaning for business
• Do engineering not over engineering
• Insist on multiple iterations
• Use business process needs to compare offerings
• Hire help
• Plan for enterprise convergence
• Change is inevitable
• Work in cooperation with process improvement (Six Sigma, Reengineering, Lean etc) initiatives.
DON’T
• Revolution in process engineering
• Go overboard with process performance metrics
• Wait for complete consensus on the new process before getting something up and running
• Allow Scope creep
• Focus on technology instead of Business functionality of BPMS
• Try implement complex process in first go
• Start with an low hanging fruits – easy to implement, least politicized
• Document the process in detail
• Establish a simple ROI metric for initiative that is meaning for business
• Do engineering not over engineering
• Insist on multiple iterations
• Use business process needs to compare offerings
• Hire help
• Plan for enterprise convergence
• Change is inevitable
• Work in cooperation with process improvement (Six Sigma, Reengineering, Lean etc) initiatives.
DON’T
• Revolution in process engineering
• Go overboard with process performance metrics
• Wait for complete consensus on the new process before getting something up and running
• Allow Scope creep
• Focus on technology instead of Business functionality of BPMS
• Try implement complex process in first go
Subscribe to:
Posts (Atom)


